
File size: 17,287 Bytes
7d0ce72 4a8a164 7d0ce72 d0e11b7 7d0ce72 062a9c4 7d0ce72 4f91add 7d0ce72 328ebc6 144afc2 328ebc6 7d0ce72 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-30B-A3B-Thinking-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
Over the past three months, we have continued to scale the **thinking capability** of Qwen3-30B-A3B, improving both the **quality and depth** of reasoning. We are pleased to introduce **Qwen3-30B-A3B-Thinking-2507**, featuring the following key enhancements:
- **Significantly improved performance** on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- **Markedly better general capabilities**, such as instruction following, tool usage, text generation, and alignment with human preferences.
- **Enhanced 256K long-context understanding** capabilities.
**NOTE**: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
## Model Overview
**Qwen3-30B-A3B-Thinking-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only thinking mode. Meanwhile, specifying `enable_thinking=True` is no longer required.**
Additionally, to enforce model thinking, the default chat template automatically includes `<think>`. Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
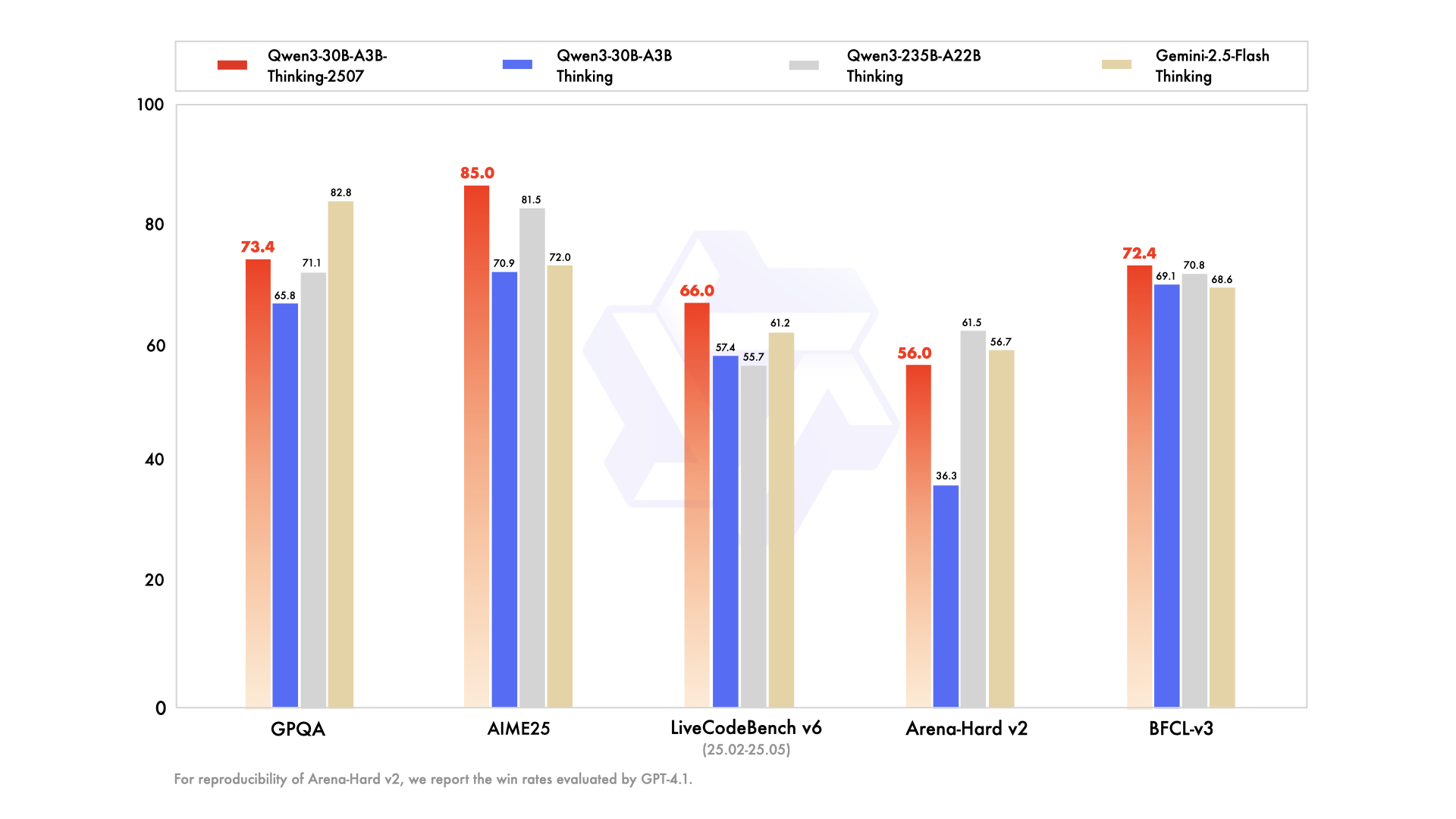
## Performance
| | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 81.9 | **82.8** | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | **92.7** | 89.5 | 91.4 |
| GPQA | **82.8** | 71.1 | 65.8 | 73.4 |
| SuperGPQA | 57.8 | **60.7** | 51.8 | 56.8 |
| **Reasoning** | | | | |
| AIME25 | 72.0 | 81.5 | 70.9 | **85.0** |
| HMMT25 | 64.2 | 62.5 | 49.8 | **71.4** |
| LiveBench 20241125 | 74.3 | **77.1** | 74.3 | 76.8 |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 61.2 | 55.7 | 57.4 | **66.0** |
| CFEval | 1995 | **2056** | 1940 | 2044 |
| OJBench | 23.5 | **25.6** | 20.7 | 25.1 |
| **Alignment** | | | | |
| IFEval | **89.8** | 83.4 | 86.5 | 88.9 |
| Arena-Hard v2$ | 56.7 | **61.5** | 36.3 | 56.0 |
| Creative Writing v3 | **85.0** | 84.6 | 79.1 | 84.4 |
| WritingBench | 83.9 | 80.3 | 77.0 | **85.0** |
| **Agent** | | | | |
| BFCL-v3 | 68.6 | 70.8 | 69.1 | **72.4** |
| TAU1-Retail | 65.2 | 54.8 | 61.7 | **67.8** |
| TAU1-Airline | **54.0** | 26.0 | 32.0 | 48.0 |
| TAU2-Retail | **66.7** | 40.4 | 34.2 | 58.8 |
| TAU2-Airline | 52.0 | 30.0 | 36.0 | **58.0** |
| TAU2-Telecom | **31.6** | 21.9 | 22.8 | 26.3 |
| **Multilingualism** | | | | |
| MultiIF | 74.4 | 71.9 | 72.2 | **76.4** |
| MMLU-ProX | **80.2** | 80.0 | 73.1 | 76.4 |
| INCLUDE | **83.9** | 78.7 | 71.9 | 74.4 |
| PolyMATH | 49.8 | **54.7** | 46.1 | 52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
\& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507 --context-length 262144 --reasoning-parser deepseek-r1
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
```
**Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
# Using Alibaba Cloud Model Studio
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507',
'model_type': 'qwen_dashscope',
}
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
# `VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --served-model-name Qwen3-30B-A3B-Thinking-2507 --tensor-parallel-size 8 --max-model-len 262144`.
#
# llm_cfg = {
# 'model': 'Qwen3-30B-A3B-Thinking-2507',
#
# # Use a custom endpoint compatible with OpenAI API:
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
# 'api_key': 'EMPTY',
# 'generate_cfg': {
# 'thought_in_content': True,
# },
# }
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **240 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-30B-A3B-Thinking-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-30B-A3B-Thinking-2507 \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85 \
--enable-reasoning --reasoning-parser deepseek_r1
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-30B-A3B-Thinking-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 4 \
--chunked-prefill-size 131072 \
--reasoning-parser deepseek-r1
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 4` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B (Thinking) | 70.6 | 96.7 | 94.4 | 94.5 | 93.4 | 82.6 | 78.4 | 74.5 | 70.6 | 63.1 | 60.0 | 56.3 | 51.0 | 48.4 | 47.2 | 48.2 |
| Qwen3-30B-A3B-Thinking-2507 (Full Attention) | 91.4 | 99.6 | 100.0| 99.8 | 99.2 | 97.4 | 96.8 | 96.8 | 94.8 | 89.4 | 90.2 | 84.0 | 82.6 | 81.9 | 80.1 | 77.5 |
| Qwen3-30B-A3B-Thinking-2507 (Sparse Attention) | 91.5 | 100.0| 99.2 | 99.1 | 98.5 | 97.3 | 97.1 | 96.9 | 95.8 | 89.0 | 89.3 | 85.5 | 84.8 | 80.0 | 79.9 | 79.6 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
* To avoid overly verbose reasoning, we set the thinking budget to 8,192 tokens.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
``` |