
ILLUME+ Models
Collection
5 items
•
Updated
![]()
🤗 ILLUME-Models |
📄 Paper |
🌐 Project-Page |
💻 Github |
💻 DualViTok(Vision Tokenizer)
🤗 ILLUME-Demo
We present ILLUME+ that leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super-resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified Multimodal Large Language Model (MLLM) and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications.
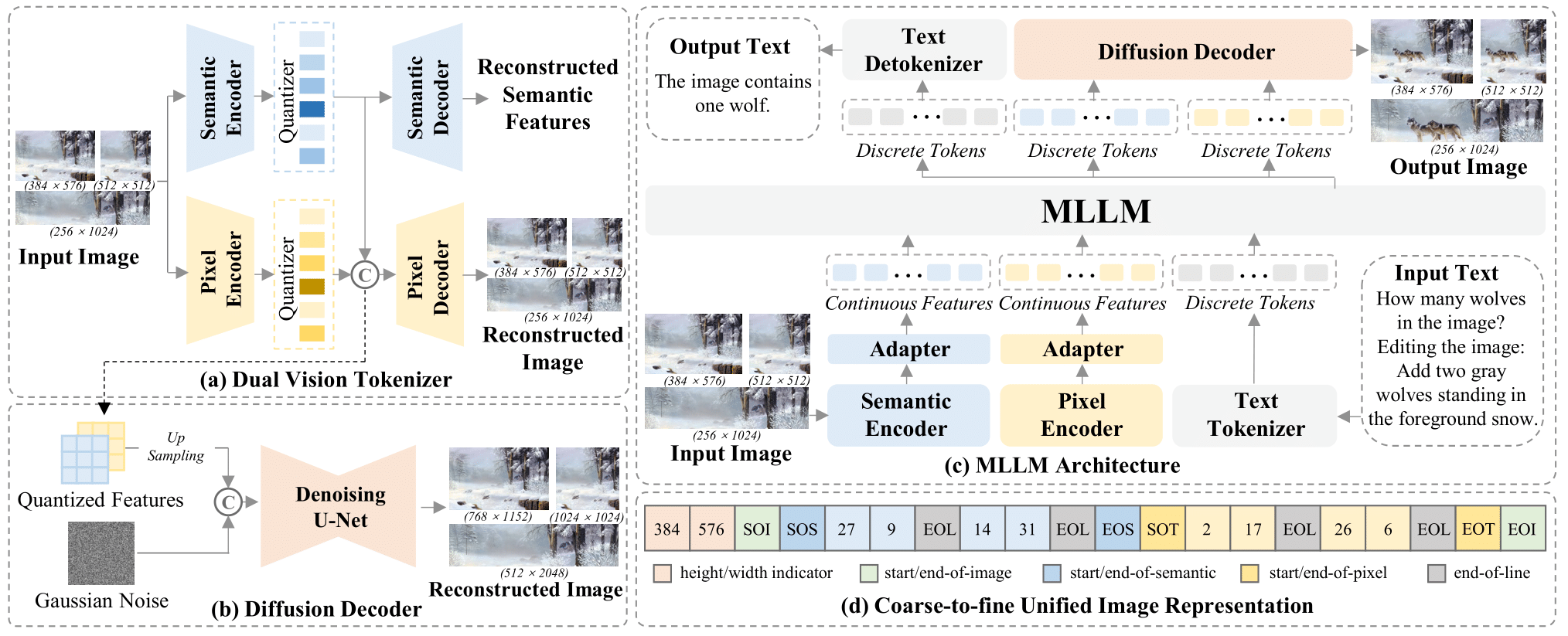
This repo contains the ILLUME_plus-Qwen2.5-3B checkpoint organized in the HuggingFace format, and thus, can be directly loaded with transformers Auto APIs.
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
### Uncomment if you want to use Ascend NPUs
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
# prepare models and processors
model = AutoModel.from_pretrained(
"ILLUME-MLLM/illume_plus-qwen2_5-7b-hf",
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2', # OR 'sdpa' for Ascend NPUs
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained("ILLUME-MLLM/illume_plus-qwen2_5-7b-hf", trust_remote_code=True)
inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "What's shown in this image?"}]},
],
images=[Image.open('path/to/image1')]
)
# run processors
inputs = processor(**inputs, return_tensors="pt")
inputs = inputs.to(model.device)
gen_kwargs = dict(
max_new_tokens=2048, do_sample=False
)
# run generation
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(processor.batch_decode(outputs, skip_special_tokens=True))
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
### Uncomment if you want to use Ascend NPUs
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
# prepare models and processors
model = AutoModel.from_pretrained(
"ILLUME-MLLM/illume_plus-qwen2_5-7b-hf",
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2', # OR 'sdpa' for Ascend NPUs
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained("ILLUME-MLLM/illume_plus-qwen2_5-7b-hf", trust_remote_code=True)
# set the vision tokenizer for decoding image.
dualvitok = AutoModel.from_pretrained('ILLUME-MLLM/dualvitok', trust_remote_code=True)
processor.set_vision_tokenizer(dualvitok)
# (Optional): set the sdxl diffusion decoder. It will enable upsample 2x image resolution.
processor.load_diffusion_vision_detokenizer("ILLUME-MLLM/dualvitok-sdxl-decoder")
target_image_resolution = (512, 512)
### Processing the prompt for image generation
# "Generate an image of {resolution_tag}, the content of image is {content}\n"
image_content='a cat'
resolution_tag = processor.get_resolution_tag_from_resolution(target_image_resolution)
prompt = processor.default_generation_template.format(resolution_tag=resolution_tag, content=image_content)
# "Generate a random image of {resolution_tag}\n"
uncond_prompt = processor.default_generation_unconditional_template.format(resolution_tag=resolution_tag)
inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "text", "text": prompt}]}
]
)
# If using the classifier-free guidance please set the unconditional prompt
# It's only needed with guidance_scale > 1.0
uncond_inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "text", "text": uncond_prompt}]}
]
)
### End of processing the prompt for image generation
# run processors
inputs = processor(**inputs, return_tensors="pt")
inputs = inputs.to(model.device)
uncond_inputs = processor(**uncond_inputs, return_tensors="pt")
uncond_inputs = uncond_inputs.to(model.device)
# prepare generation arguments
gen_kwargs = dict(
max_new_tokens=2048, do_sample=True,
)
image_gen_kwargs = dict(
negative_image_prompt_ids=uncond_inputs.input_ids,
negative_image_prompt_attention_mask=uncond_inputs.attention_mask,
target_image_resolution=target_image_resolution,
guidance_scale=2.0,
image_semantic_temperature=1.0,
image_semantic_top_k=2048,
image_semantic_top_p=1.0,
image_pixel_temperature=1.0,
image_pixel_top_k=2048 * 3,
image_pixel_top_p=1.0,
)
# run generation
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs, **image_gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
outputs_text = processor.batch_decode(outputs, skip_special_tokens=True)
# It extract the image tokens of each image and replace the image tokens with the `image_placeholder` in order.
generated_text, image_embed_inds_list, list_image_token_parts = processor.parse_text_image(outputs_text[0],
image_placeholder='<image_out>')
# batch decoding the image by using the DualViTok.
vq_decoded_images = processor.decode_images(image_embed_inds_list, target_resolution=target_image_resolution)
# batch decoding the image by using the sdxl diffusion decoder.
# The output image resolution would be [target_image_resolution[0] * 2, target_image_resolution[1] * 2]
diffusion_decoded_images = processor.decode_images(image_embed_inds_list, target_resolution=target_image_resolution,
use_diffusion=True, diffusion_cfg_scale=2.0,
diffusion_num_inference_steps=20)
vq_decoded_images[0].save('vq_decoded_cat.png')
diffusion_decoded_images[0].save('diffusion_decoded_cat.png')
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
### Uncomment if you want to use Ascend NPUs
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
# prepare models and processors
model = AutoModel.from_pretrained(
"ILLUME-MLLM/illume_plus-qwen2_5-7b-hf",
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2', # OR 'sdpa' for Ascend NPUs
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained("ILLUME-MLLM/illume_plus-qwen2_5-7b-hf", trust_remote_code=True)
# set the vision tokenizer for decoding image.
dualvitok = AutoModel.from_pretrained('ILLUME-MLLM/dualvitok', trust_remote_code=True)
processor.set_vision_tokenizer(dualvitok)
# (Optional): set the sdxl diffusion decoder. It will enable upsample 2x image resolution.
processor.load_diffusion_vision_detokenizer("ILLUME-MLLM/dualvitok-sdxl-decoder")
### Processing the prompt for image Editing
source_image_path='path/to/image.png'
instruction='Your Editing Instruction'
image = Image.open(source_image_path)
original_size = image.size
image = processor.transform_image_nearest_resolution_ratio(image)
target_resolution = image.size[::-1]
resolution_tag = processor.get_resolution_tag_from_resolution(target_resolution)
# "{resolution_tag}<image>\nPlease edit the image according to the instruction: {content}\n"
editing_prompt = processor.default_editing_template.format(resolution_tag=resolution_tag, content=instruction)
inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type", "image"}, {"type": "text", "text": editing_prompt},]}
],
images=[image]
)
# CFG unconditional prompt for image editing.
# "{resolution_tag}<image>\nReconstruct the image according to the given image\n"
uncond_prompt = processor.default_editing_unconditional_template.format(resolution_tag=resolution_tag)
uncond_inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type", "image"}, {"type": "text", "text": uncond_prompt}]}
],
images=[image]
)
### End of processing the prompt for image editing
# run processors
inputs = processor(**inputs, return_tensors="pt")
inputs = inputs.to(model.device)
uncond_inputs = processor(**uncond_inputs, return_tensors="pt")
uncond_inputs = uncond_inputs.to(model.device)
# prepare generation arguments
image_gen_kwargs = dict(
negative_image_prompt_ids=uncond_inputs.input_ids,
negative_image_prompt_attention_mask=uncond_inputs.attention_mask,
target_image_resolution=target_image_resolution,
guidance_scale=1.5,
image_semantic_temperature=0.8,
image_semantic_top_k=512,
image_semantic_top_p=0.8,
image_pixel_temperature=0.8,
image_pixel_top_k=512 * 3,
image_pixel_top_p=0.8,
)
gen_kwargs = dict(
max_new_tokens=2048, do_sample=True
)
# run generation
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs, **image_gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
outputs_text = processor.batch_decode(outputs, skip_special_tokens=True)
# It extract the image tokens of each image and replace the image tokens with the `image_placeholder` in order.
generated_text, image_embed_inds_list, list_image_token_parts = processor.parse_text_image(outputs_text[0],
image_placeholder='<image_out>')
# batch decoding the image by using the DualViTok.
vq_decoded_images = processor.decode_images(image_embed_inds_list, target_resolution=target_image_resolution)
# batch decoding the image by using the sdxl diffusion decoder.
# The output image resolution would be [target_image_resolution[0] * 2, target_image_resolution[1] * 2]
diffusion_decoded_images = processor.decode_images(image_embed_inds_list, target_resolution=target_image_resolution,
use_diffusion=True, diffusion_cfg_scale=2.0,
diffusion_num_inference_steps=20)
vq_decoded_images_unpadded = processor.unpad_and_resize_back(vq_decoded_images[0], *original_size)
diffusion_decoded_images_unpadded = processor.unpad_and_resize_back(diffusion_decoded_images[0], *original_size)
vq_decoded_images_unpadded.save('vq_decoded_edited_image.png')
diffusion_decoded_images_unpadded.save('diffusion_decoded_edited_image.png')
Note that we implement InterleavedLogitsProcessor in inference for three key reasons:
<start_of_image> tokens.do_sample=True is enabled during text or image generation.@article{huang2025illume+,
title={Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement},
author={Huang, Runhui and Wang, Chunwei and Yang, Junwei and Lu, Guansong and Yuan, Yunlong and Han, Jianhua and Hou, Lu and Zhang, Wei and Hong, Lanqing and Zhao, Hengshuang and others},
journal={arXiv preprint arXiv:2504.01934},
year={2025}
}