🚀 Best Practices for Evaluating the Qwen3-VL Model

The Qwen3-VL series represents the most powerful visual language model in the Qwen lineup to date, achieving comprehensive advancements across multiple dimensions: whether in pure text comprehension and generation, or in the perception and reasoning of visual content; whether in the ability to support context length, or in the depth of understanding spatial relationships and dynamic videos; and even in interactions with agents, Qwen3-VL demonstrates significant progress.
In this best practice guide, we will use the EvalScope framework to conduct a thorough evaluation of the Qwen3-VL model, covering both model service inference performance and model capability assessments.
Installing Dependencies
First, install the EvalScope model evaluation framework:
pip install 'evalscope[app,perf]' -U
Model Service Inference Performance Evaluation
For multimodal models, we need to access model capabilities through an OpenAI API-compatible inference service for evaluation, as local inference using transformers is not yet supported. Besides deploying the model to cloud services that support OpenAI interfaces, you can also choose to locally launch the model using frameworks like vLLM or ollama. These inference frameworks can efficiently handle multiple concurrent requests, thereby accelerating the evaluation process.
DashScope API Service Performance Evaluation
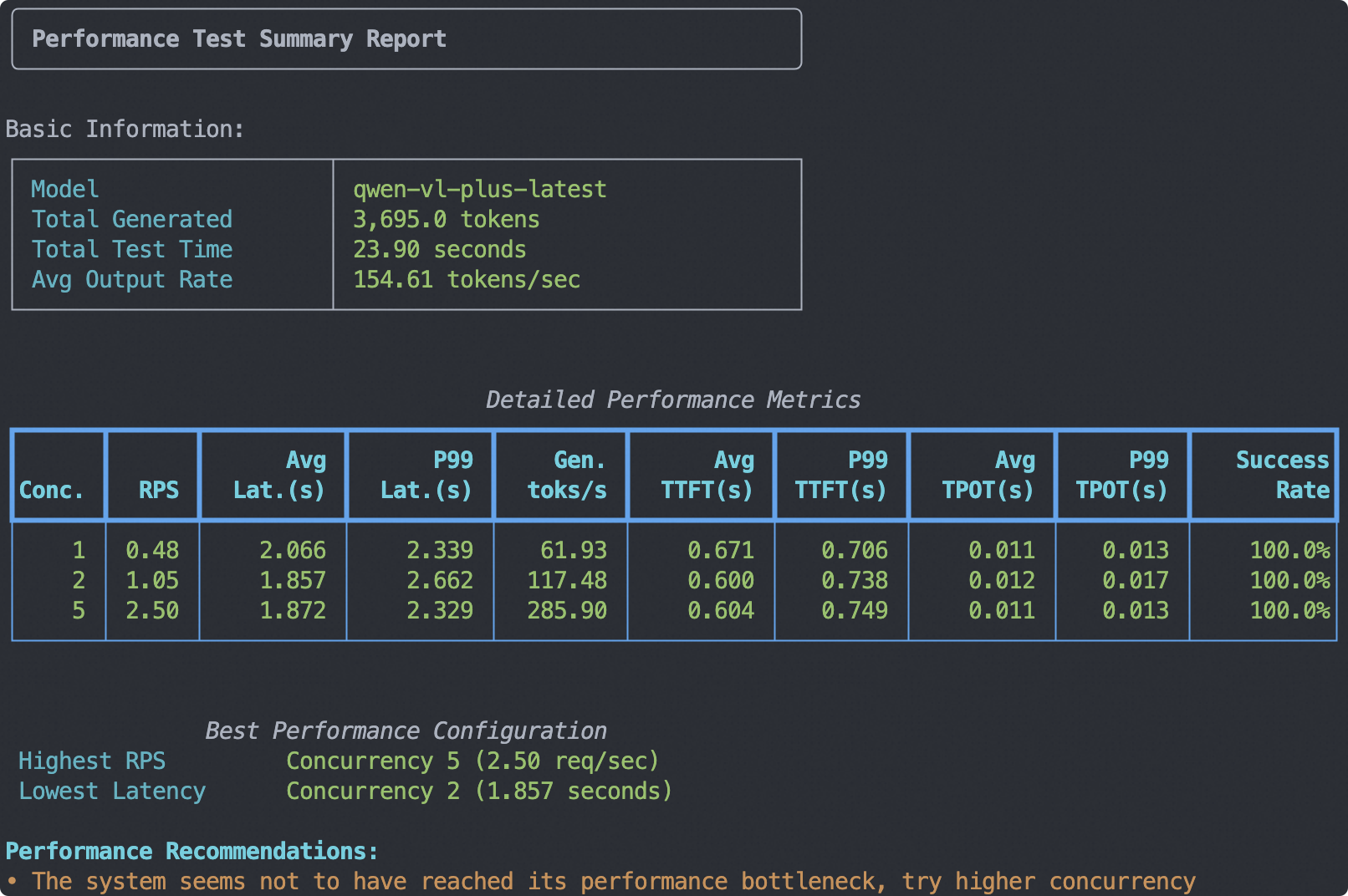
Given the large number of model parameters, we will use the API provided by the DashScope platform to access Qwen3-VL (the corresponding model on the platform is qwen-vl-plus-latest) and conduct stress testing on the model service.
TIP: You can also use the free API provided by ModelScope for trial purposes. For details, refer to: https://modelscope.cn/docs/model-service/API-Inference/intro
Stress Test Command:
- Input: 100 tokens of text + 1 image of 512x512
- Output: 128 tokens
evalscope perf \
--model qwen-vl-plus-latest \
--url https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
--api-key "API_KEY" \
--parallel 1 2 5 \
--number 4 8 20 \
--api openai \
--dataset random_vl \
--min-tokens 128 \
--max-tokens 128 \
--prefix-length 0 \
--min-prompt-length 100 \
--max-prompt-length 100 \
--image-width 512 \
--image-height 512 \
--image-format RGB \
--image-num 1 \
--tokenizer-path Qwen/Qwen3-VL-235B-A22B-Instruct
The output report is as follows:
Model Capability Evaluation
Next, we proceed with the model capability evaluation process.
Note: Subsequent evaluation processes are based on API model services. You can launch the model service according to the model inference framework usage steps.
Constructing an Evaluation Set (Optional)
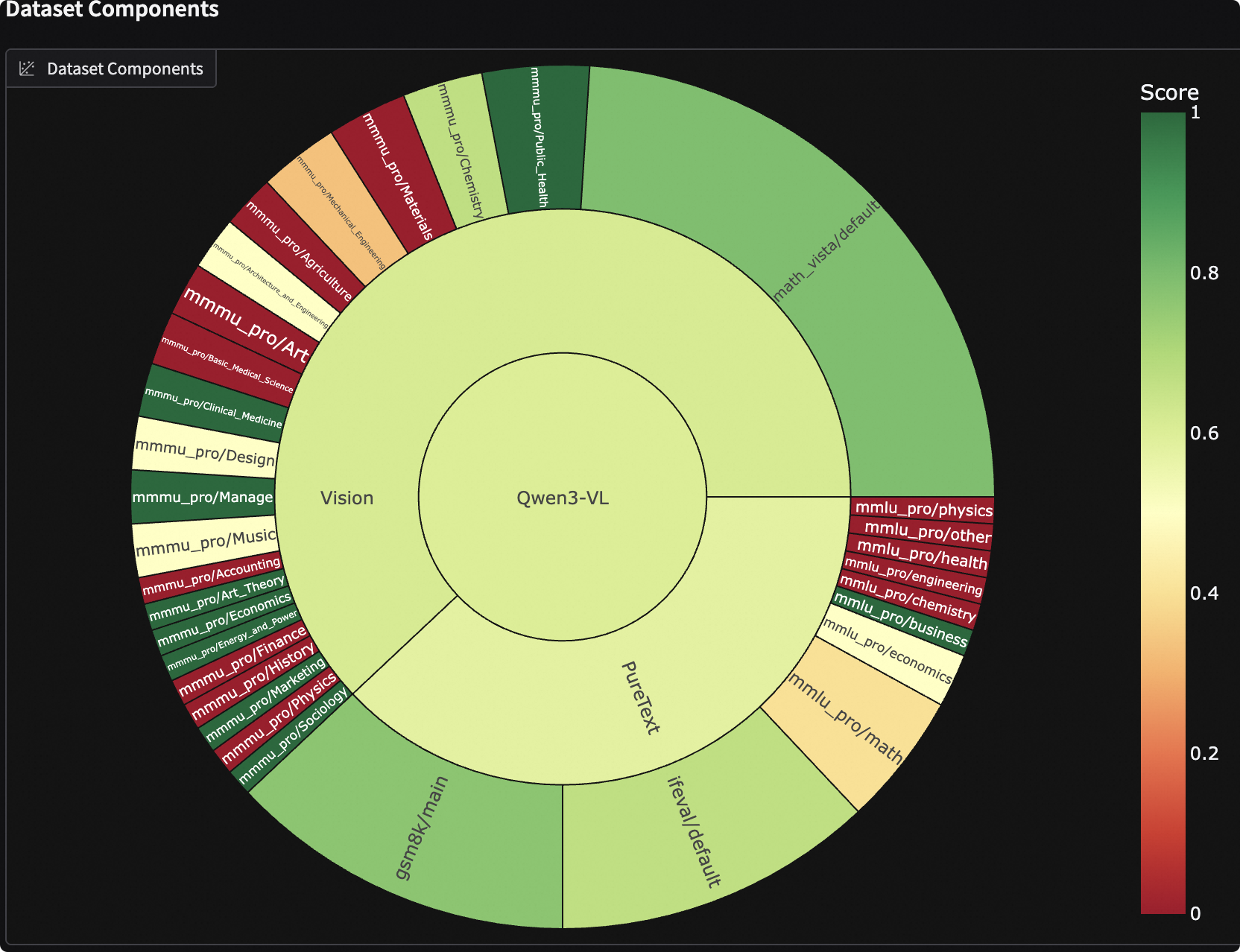
To comprehensively assess the model's capabilities, we can mix benchmarks already supported by EvalScope to construct a comprehensive evaluation set. Below is an example of an evaluation set that covers mainstream benchmarks, evaluating the model's mathematical ability (GSM8K), knowledge ability (MMLU-Pro), instruction following (IFEval), multimodal knowledge ability (MMMU-Pro), and multimodal mathematical ability (MathVista), among others.
Run the following code to automatically download and mix datasets based on the defined schema, and save the constructed evaluation set in a local JSONL file. Of course, you can skip this step and directly use the processed data set we placed in the ModelScope repository.
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_data
schema = CollectionSchema(name='Qwen3-VL', datasets=[
CollectionSchema(name='PureText', weight=1, datasets=[
DatasetInfo(name='mmlu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='ifeval', weight=1, task_type='instruction', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='gsm8k', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Vision', weight=2, datasets=[
DatasetInfo(name='math_vista', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='mmmu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
])
])
# get the mixed data
mixed_data = WeightedSampler(schema).sample(1000)
# dump the mixed data to a jsonl file
dump_jsonl_data(mixed_data, 'outputs/qwen3_vl_test.jsonl')
Running the Evaluation Task
Run the following code to evaluate the performance of the Qwen3-VL model:
from dotenv import dotenv_values
env = dotenv_values('.env')
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
task_cfg = TaskConfig(
model='qwen-vl-plus-latest',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=env.get('DASHSCOPE_API_KEY'),
eval_type=EvalType.SERVICE,
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'evalscope/Qwen3-VL-Test-Collection',
}
},
eval_batch_size=5,
generation_config={
'max_tokens': 30000, # Maximum number of tokens to generate, recommended to set to a large value to avoid output truncation
'temperature': 0.6, # Sampling temperature (recommended value from Qwen report)
'top_p': 0.95, # Top-p sampling (recommended value from Qwen report)
'top_k': 20, # Top-k sampling (recommended value from Qwen report)
'n': 1, # Number of responses generated per request
},
limit=100, # Set to 100 data points for testing
)
run_task(task_cfg=task_cfg)
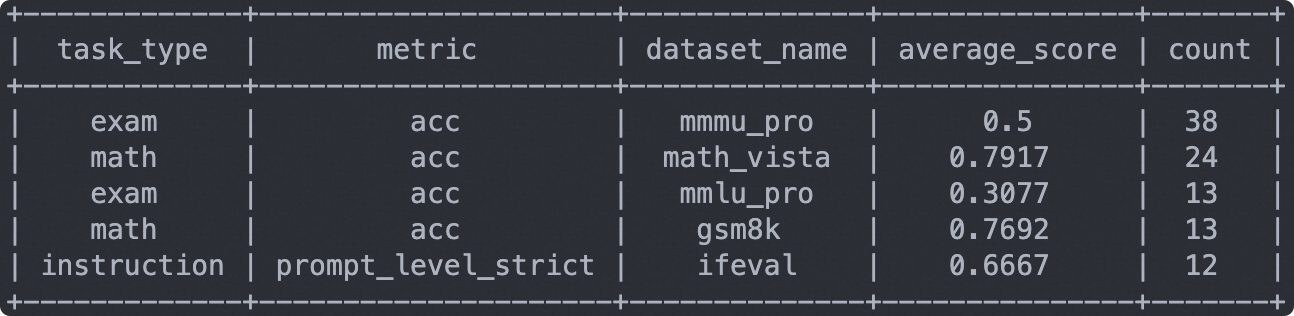
The output results are as follows:
Note: The following results are based on 100 data points, used only for testing the evaluation process. The limit should be removed for formal evaluation.
Visualization of Evaluation Results
EvalScope supports result visualization, allowing you to view the specific outputs of the model.
Run the following command to launch a Gradio-based visualization interface:
evalscope app
Select the evaluation report, click load, and you will see the model's output for each question, as well as the overall accuracy rate: